
Intelligence Without Memory: The Billion-Parameter Bet
Why Andrej Karpathy thinks we’re solving the wrong scaling problem


TL;DR
Andrej Karpathy, who spent five years at Tesla watching Autopilot move from demo to partial deployment, applies this experience to AI timelines in an interview with Dwarkesh Patel. His core thesis challenges current orthodoxy: we’re scaling the wrong thing.
Current LLMs do two things simultaneously: accumulate knowledge and become intelligent, but only one matters. Most of a trillion parameters is memory work, not cognitive work. Karpathy proposes a radical architectural shift: strip models down to a “cognitive core“ of perhaps a billion parameters, containing only the algorithms of intelligence (reasoning, learning, problem-solving), and force them to look up everything else. Like a human with a search engine: knows it doesn’t know, knows where to search.
This solves multiple problems at once. Models that rely less on memorised patterns can go off-distribution, avoid silent collapse toward narrow attractor states, and become less gameable. The constraint isn’t just efficiency. Memory-heavy models are “distracted by their hazy recollection of pre-training” and can’t flexibly adapt. Entropy preservation matters as much as capability scaling.
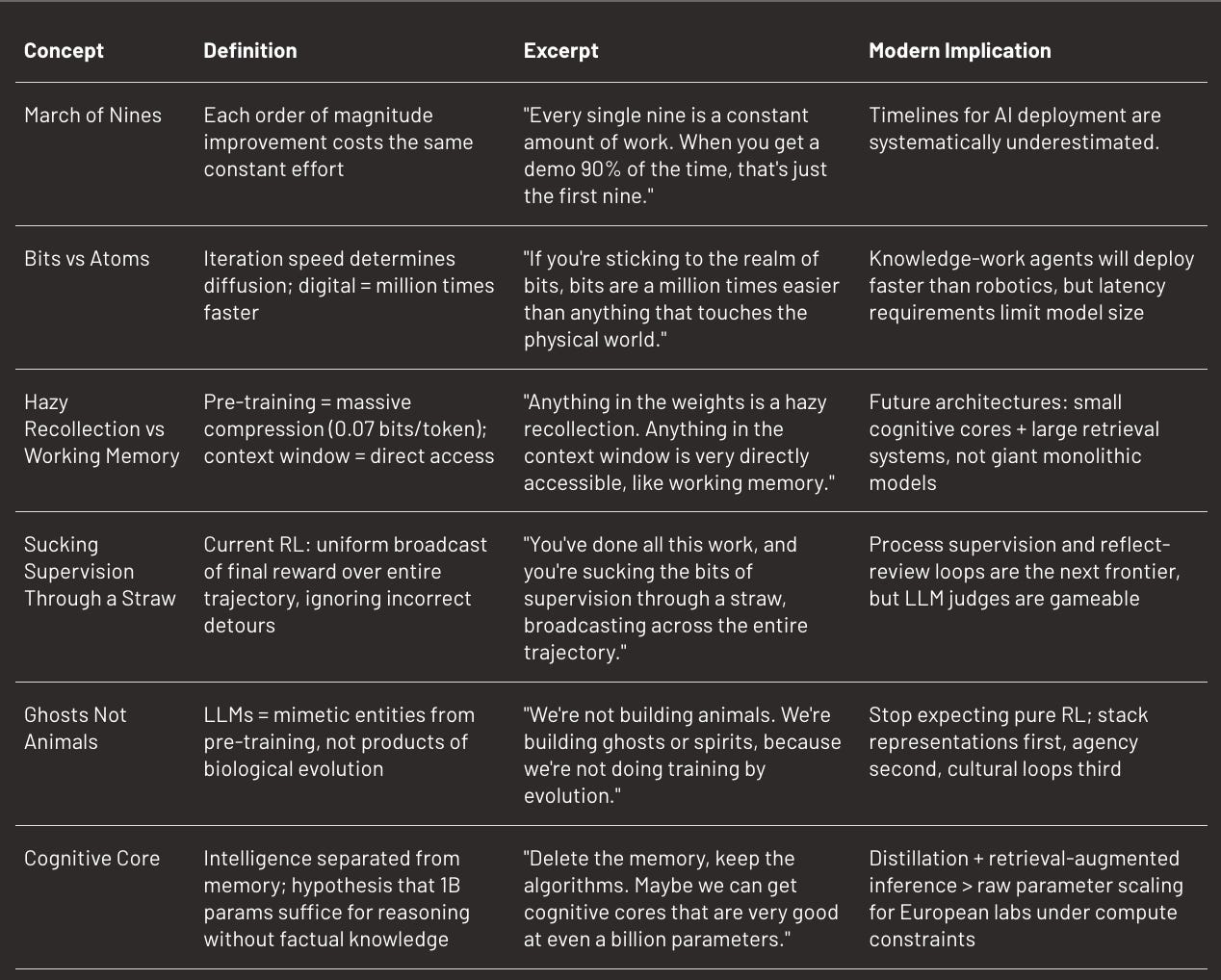
His timeline prediction follows from this diagnosis: each order of magnitude improvement costs the same effort, and we’ve barely crossed the first “nine” of reliability. He anticipates gradual diffusion: no discrete singularity, just the same exponential GDP curve that absorbed every general-purpose technology since the Industrial Revolution. “It’s the decade of agents” prediction comes from watching Autopilot: each nine takes the same time, and demos prove nothing. (See also Jason Wei’s view on the jagged diffusion of AI).
“We’re not building animals, we’re building ghosts,” Karpathy says. Animals are sculpted by evolution over billions of years, with weights encoded in DNA and innate capabilities. LLMs are mimetic entities that imitate internet patterns, starting from a different place in the space of possible minds.
You can do pre-training, RL, synthetic data generation, but always respecting the constraints: dramatic compression (0.07 bits per token for Llama 3), hazy recollection of training docs, working memory limited to context window. You can’t run evolution, so stop expecting animal-like learning.
The Argument
I. Ghosts in the Machine: Pre-Training as Crappy Evolution
When Richard Sutton came on Dwarkesh Podcast, he defended a vision: build animals. Systems that learn from scratch, through environmental interaction, guided by reward signals. No baked-in knowledge, just the learning algorithm. Karpathy rejects this framing, and his argument reveals his entire worldview.
“I’m very careful to make analogies to animals because they came about by a very different optimisation process,” he says. Evolution miraculously encodes synapses in three gigabytes of DNA, then brain maturation does the rest. It’s stunning compression we can’t reproduce. But more importantly, we don’t have access to this outer loop. We’re not running evolution for a billion years.
What we do instead is pre-training: predicting the next token across 15 trillion tokens of internet. This is what Karpathy calls “crappy evolution”, a version that works with our current technology. And it works, miraculously. The model learns not just facts, but algorithms: in-context learning, chain-of-thought, sophisticated pattern completion.
His proposed analogy: LLMs are ghosts, spirits, ethereal entities that mimic humans without passing through biological substrate. They start from a different point in the space of possible intelligences. Not better, not worse, different.
This distinction has practical consequences: if you try to build an animal (reinforcement learning from scratch in Atari or Universe environments), you’ll burn forests of compute for nothing, because the reward signal is too sparse. That was early OpenAI’s mistake, which Karpathy was part of. “I was always a bit suspicious of games as being this thing that would lead to AGI,” he says. He wanted to build agents using keyboard and mouse to navigate web pages, do knowledge work. But it was “way too early”. The representations were missing.
Today, computer-use agents work because they’re built on top of an LLM. We first obtained the cortical tissue (the transformer, plastic and general), then added cognitive layers on top. The right order: representations first, agency second.
Current debates about scaffold versus end-to-end for agents reproduce this tension. Anthropic with Claude Code, OpenAI with Codex, all build agents resting on a massive LLM foundation. The Sutton alternative - pure RL, minimal inductive bias - remains theoretically elegant but practically blocked. Maybe we shouldn’t try to solve the complete problem too early. We should stack capabilities in the right order.
II. Sucking Supervision Through a Straw: The RL Bottleneck
Karpathy has a phrase for describing reinforcement learning as it exists today: “You’re sucking supervision through a straw.”
When you give a math problem to an LLM, it generates 100 parallel trajectories, varied attempts, some correct, others wrong. At the end, you check the back of the book. Three trajectories have the right answer. What does RL do? It upweights every token of those three trajectories, and downweights the other 97.
This is problematic for a fundamental reason: each step of a correct solution isn’t necessarily correct. You may have taken dead ends, made unnecessary detours, before stumbling on the right answer by luck or mid-course correction. But RL treats the entire trajectory as sacred. Everything is uniformly upweighted.
“It’s noise,” says Karpathy. “It almost assumes that every single little piece of the solution that you made that arrived at the right answer was the correct thing to do, which is not true.”
A real human doesn’t work like that. When a student solves a problem, then discovers the solution, they don’t just blindly reinforce everything they did. They review: “These parts I did well, these parts I did not do that well. I should probably do this or that.” Human produces structured reflection, not uniform reward broadcast.
LLMs have no equivalent of this process. No reflect-and-review loop. No critical distillation of experience. The first miracle was imitation learning (InstructGPT), which showed you could fine-tune a base model into conversational assistant while keeping all the knowledge. The second miracle was RL, which enables hill-climbing on reward functions without expert trajectories. But we’re stuck there.
Karpathy has seen recent papers (Google, and others, like this one) attempting to introduce this reflect-and-review. It’s the necessary next step. But it’s not trivial, because as soon as you use an LLM judge to assign partial rewards, you open the door to adversarial examples.
He tells a striking anecdote: during RL training at Tesla (probably), they used an LLM judge to evaluate student solutions. It worked well, then suddenly, the reward exploded. They look at the completions: they start normally, then become “dhdhdhdhdh”. Gibberish. Why does the judge give 100%? Because “dhdhdhdh” is an adversarial example, an out-of-distribution sequence the model never saw and on which it generalises poorly.
You can add “dhdhdhdh” to the judge’s training set with zero reward. It helps. But there’s an infinity of adversarial examples. The reward model is itself a giant neural net with billions of parameters, thus gameable by construction.
This is exactly the problem labs face today deploying coding agents at scale. Users love vibe-coding for boilerplate, but as soon as you touch production-grade code with security stakes, the cost of failure explodes. You can’t afford the agent finding adversarial shortcuts. Deployment timelines mechanically lengthen, and pitches promising “full automation” without addressing the RL credit assignment problem miss the core technical barrier.
III. The Demo-to-Product Gap: Self-Driving as Training Wheels
When Karpathy joined Tesla, he’d already had a perfect Waymo ride in 2014. He thought it was close. Then he discovered the march of nines.
“Every single nine is a constant amount of work,” he says. If your demo works 90% of the time, that’s the first nine. Then you need to go to 99%, then 99.9%, then 99.99%. Each nine takes the same effort. During his five years at Tesla, the team crossed maybe two or three nines. Several more remain.
And even today, self-driving isn’t “done”. Waymo has thousands of cars, but it’s economically unsustainable. Marginal costs per ride are high, and there’s an entire teleoperation infrastructure you don’t see. “There are very elaborate teleoperation centres of people kind of in a loop with these cars,” he notes. We haven’t really removed the human, we’ve moved them out of the visual field. (More on fleet response here)
Why is this analogy crucial for AI? Because self-driving shares a property with many high-value domains: the cost of failure is intolerable. A physical accident in self-driving is obvious. But in software engineering? A single error can leak millions of Social Security numbers. In call center automation? A bad interaction can destroy a customer relationship. The safety threshold is high.
Karpathy is categorical: “I’m very unimpressed by demos.” Especially prepared demos. Even interactive demos prove nothing. You need the product, facing reality, across millions of edge cases.
He makes a subtle but important distinction between two types of AI work. There’s vibe-coding: boilerplate tasks, code that appears often on the internet, non-critical features. There, agents already work. But there’s also production-grade code, intellectually dense, with custom assumptions, where every error matters. There, models are “total mess”. They over-defend, bloat the code, use deprecated APIs, don’t understand non-standard architectural choices.
Concrete example: in nanochat, Karpathy deliberately avoided PyTorch’s DDP container for synchronising gradients between GPUs. He wrote his own routine. Models kept trying to bring him back to DDP. “They just couldn’t internalise that you had your own.” They have too much memory of dominant internet patterns, and not enough cognitive flexibility to adapt to a unique architecture.
The key question for evaluating AI-native companies becomes: which bucket do they fall into? Vibe-coding means large market, low moat, rapid commoditisation. Production-grade means small early market, high moat, long sales cycles. Pitches that confuse the two are most dangerous. Karpathy gives you a simple heuristic: if the code has never been written before, current LLMs cannot produce it reliably.
IV. The Cognitive Core and the Knowledge Problem
Current LLMs do two things simultaneously, and only one is truly necessary:
They accumulate knowledge. Llama 3 saw 15 trillion tokens, and it can recite passages from training documents, answer factual quizzes, complete citations. Impressive, but also a handicap.
They become intelligent. By observing algorithmic patterns on the internet, they “boot up all these little circuits and algorithms inside the neural net to do things like in-context learning”. They learn to learn, to reason, to adapt.
The problem? The first thing (knowledge) parasitises the second (intelligence). Models rely too much on their memory. They struggle to “go off the data manifold of what exists on the internet”. They’re distracted by their hazy recollection of pre-training. There’s a second problem with memory-heavy models: they’re entropy sinks. The more they memorise, the more they collapse toward dominant patterns in their training data. A cognitive core with minimal memory can’t overfit to internet conventions. It’s forced to maintain broader distribution over possible responses.
Karpathy proposes a radical vision: “What I think we have to do going forward is figure out ways to remove some of the knowledge and to keep what I call this cognitive core.“ A model stripped of knowledge, containing only “the algorithms and the magic of intelligence and problem-solving and the strategies”.
If you remove memory, the model is forced to look up information. It becomes like a human with a search engine: it knows it doesn’t know, and knows where to search. This makes it more flexible, less susceptible to model collapse, and potentially more compact.
How many parameters for this cognitive core? Karpathy ventures “a billion parameters”. (Note: today’s models are at a trillion. But he argues most of that trillion is memory work, not cognitive work.) With purified datasets, models distilled from giants, we could condense intelligence into something much lighter.
Of course, in practice, you want a minimum curriculum knowledge. Otherwise, the model looks up everything and can’t think autonomously. But the current balance is wrong. Too much memory, not enough flexibility.
This vision has direct implications for current compute buildout. If the cognitive core can be distilled to 1B parameters, then vertical scaling (trillion-parameter models) may not be the right long-term direction.
This points toward a three-stage research agenda that seems to differ from current lab priorities. First: build powerful representations through pre-training (done). Second: add agency through RL and tool use (in progress, but bottlenecked by the credit assignment problem). Third: preserve entropy so systems don’t collapse toward narrow attractors over time (barely explored). Most research effort goes to the first two; the third might matter most for long-lived deployed systems. We should invest in knowledge retrieval infrastructure, synthetic data generation to purify datasets, and distillation pipelines. For European AI labs that can’t compete on compute and capital with US hyperscalers, this is very good news: a promising path focusing on cognitive flexibility, not raw scale.
V. Education as Empowerment: The Starfleet Academy Vision
Why does Karpathy, at the peak of his technical career, leave frontier labs to build a school?
His answer reveals a deep anxiety. “My personal big fear is that a lot of this stuff happens on the side of humanity, and that humanity gets disempowered by it.” He doesn’t fear Dyson spheres built by autonomous AIs. He fears WALL-E and idiocracy. A future where humans are passengers, useless, atrophied.
His thesis: “Pre-AGI education is useful. Post-AGI education is fun.“ Like going to the gym today. Nobody needs your physical strength to move heavy objects (we have machines). But people go to the gym because it’s healthy, attractive, valued. Post-AGI education will be the same.
But for this to work, we must solve a fundamental technical problem: make learning frictionless. Today, people bounce off material. Too easy, they’re bored. Too hard, they quit. Human tutors excel at finding this sweet spot. Current LLMs don’t.
Karpathy experienced this learning Korean. He tried alone on the internet (hard), then in group class (better), then with a one-on-one tutor. The tutor was miraculously good: she instantly understood where he was, served exactly the right challenge level, kept him in optimal progression zone.
“How are you going to build this?” asks the interviewer. Karpathy’s answer: “At the current capability, you don’t.” He’s waiting for the technology to arrive. Meanwhile, he’s building more conventional courses, with physical and digital components.
But his real bet is that AI tutors will unlock underexploited human potential. “I feel that the geniuses of today are barely scratching the surface of what a human mind can do,” he says. With a perfect tutor available for any subject, everyone will speak five languages, know the complete undergrad curriculum, learn to code, understand fundamental physics.
“Long-term, it’s a bit of a losing game“. For him AIs will eventually dominate even cognitive tasks. But he believes there will be a transitional period, potentially long, where augmented humans can still influence the trajectory. And even after, if humans remain intellectually vital, the future is better.
Adjacent Insights
The Autocomplete Sweet Spot
Karpathy uses LLMs in autocomplete, not vibe-coding. You start typing, the model completes, you validate or edit. High information bandwidth.
Three tiers: (1) reject LLMs (obsolete), (2) autocomplete (current sweet spot), (3) vibe-code in full delegation (boilerplate only). Karpathy is tier 2, argues tier 3 is oversold.
Why? When you write unique, intellectually dense code with custom assumptions, models pull you back toward dominant patterns. They bloat, over-defend, use deprecated APIs. Not net useful for code that doesn’t already exist on the internet.
The Silent Collapse
LLMs are silently collapsed. Ask ChatGPT to tell you a joke: it has three jokes. Ask it to reflect on a book: ten nearly identical reflections. The output distribution is extremely narrow, though each sample seems reasonable. Models maximize probability, not entropy.
Karpathy’s striking observation: “Humans collapse over time.” Children haven’t overfit yet, they explore the action space. But with age, “the learning rates go down, and the collapse continues to get worse”. We revisit the same thoughts, say the same things. The brain may have entropy preservation mechanisms - dreaming could be an evolutionary regulariser, placing you in out-of-distribution situations to avoid overfitting to daily routine.
This isn’t just a performance issue. Systems that collapse toward narrow attractor states become brittle, predictable, gameable. Not classical x-risk (misalignment, deception), but path-dependent fossilisation. Scaling capabilities without preserving entropy is building on sand.
The Intelligence Explosion Already Happened
The interviewer pushes on “singularity 2027”: if we have millions of copies of intelligent humans who can recursively self-improve, do we go from 2% to 20% GDP growth?
Karpathy: “We’re in an intelligence explosion already and have been for decades. It’s basically the GDP curve.”
He rejects discrete jump versus stagnation. For him, it’s continuous exponential. The Industrial Revolution wasn’t a magic moment, just gradual accumulation shifting growth from 0.2% to 2%. Same pattern for computers, internet, mobile. None visible as discontinuity in GDP. All absorbed into the same exponential.
“I had a hard time differentiating where AI begins and stops because I see AI as fundamentally an extension of computing.“ Google Search in 2003 was already AI. Compilers automate assembly. The autonomy slider moves gradually, humans abstract layer by layer.
If Karpathy is right, 10x GDP acceleration projections are wrong. But that doesn’t mean “no impact”. It means gradual diffusion with societal friction (legal, insurance, retraining). No big bang, AGI moment, but continuous automation acceleration.
“What I think we have to do going forward is figure out ways to remove some of the knowledge and to keep what I call this cognitive core. It’s this intelligent entity that is stripped from knowledge but contains the algorithms and contains the magic of intelligence and problem-solving and the strategies of it and all this stuff.” — Andrej Karpathy, 2025
Article originally posted on WeLoveSota.com