
LLMs Navigate Knowledge, They Do Not Create
Why Columbia CS professor Vishal Misra's formal models prove current AI architectures cannot reach AGI, no matter how much compute you add


TL;DR
Vishal Misra, a Columbia CS professor who accidentally invented RAG while trying to fix a cricket statistics website, has developed the most rigorous formal models for understanding what LLMs can and cannot do. In a recent interview with Erik Torenberg and Martin Casado on the a16z podcast, his central claim cuts against both the AGI accelerationists and the “stochastic parrot” reductionists: LLMs perform genuine Bayesian reasoning over training data, creating compressed geometric spaces they navigate with increasing sophistication, but they cannot create new ones.
Any LLM trained on pre-1915 physics could never invent relativity because Einstein had to reject Newtonian frameworks entirely. Gödel’s incompleteness theorem required stepping outside axiomatic systems. Quantum mechanics demanded abandoning classical determinism. These breakthroughs required creating entirely new conceptual frameworks, not just connecting existing ideas. Current models, regardless of parameter count or compute budget, can only connect known results in novel sequences. They fill in algorithmic gaps, interpolate between training examples, and traverse solution spaces along low-entropy paths. What they cannot do is generate the genuinely new.
This matters because Silicon Valley is betting hundreds of billions on a scaling hypothesis that Vishal Misra’s models suggest hits a fundamental wall. The field mistakes sophisticated navigation for creative capability, confusing IMO medal performance (connecting known mathematical results) with the invention of new mathematics itself.
The Accidental Theorist
Vishal Misra’s path to AI theory began with aesthetic annoyance. In the 1990s, he co-founded Cricket Info (now ESPN Cricinfo), an online cricket statistics and news portal that became the world’s most popular website before India came online, exceeding Yahoo’s traffic. The site featured Stats Guru, a searchable cricket statistics database with capabilities that required 25 checkboxes, 15 text fields, and 18 dropdown menus to access. The interface was, by his admission, a mess. Only the most dedicated nerds could navigate it.
This bothered him for years. When GPT-3 arrived in July 2020, he saw someone use it to write SQL queries from natural language and thought immediately of Stats Guru. He got early access but hit constraints fast. The backend database was too complex for GPT-3’s 2,048 token context window, and the model didn’t follow instructions reliably. So he improvised. He created a database of 1,500 natural language query examples paired with a custom domain-specific language (DSL, a specialised syntax for querying cricket statistics) he designed himself, then used semantic similarity to retrieve the six or seven most relevant examples as prompt prefix before the new query. GPT-3 completed the pattern with remarkable accuracy. The system went to production in September 2021, fifteen months before ChatGPT launched and Retrieval-Augmented Generation, a technique that enhances LLM outputs by retrieving relevant context from external knowledge bases, became industry standard.
But he had no idea why it worked. He stared at transformer architecture diagrams and read papers without breakthrough. That confusion launched his journey into formal modeling. Unlike the field’s prevailing empiricism, where researchers fiddle with prompts and measure outputs across hundreds of papers, Vishal Misra wanted mathematical precision. He wanted to understand the mechanism.
The Matrix and the Manifold
The model he developed begins with a conceptual object: imagine a matrix where every row represents a possible prompt and every column represents a token in the vocabulary. For GPT-3, with its 2,000 token context and 50,000 token vocabulary, this matrix would have more rows than atoms in all known galaxies. Each cell contains the probability of that token following that prompt.
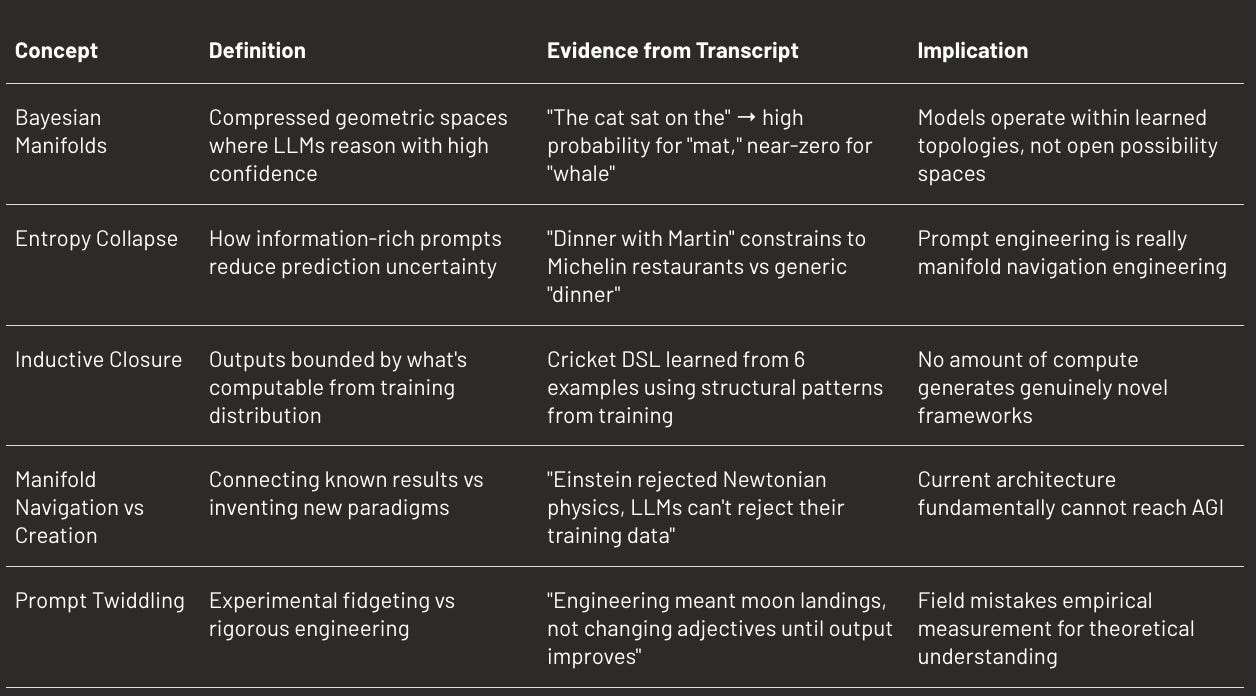
No model can represent this matrix explicitly. The matrix is catastrophically sparse: most prompts never appear in real use, and for any given prompt, most tokens have zero probability of following it. What transformers actually do is compress this impossibly large space. Through their architecture and training process, they create what Vishal Misra calls Bayesian manifolds: reduced-dimensional geometric structures that capture the high-probability regions. The model learns to reason confidently within these compressed spaces rather than trying to represent every possible prompt-token combination.
The insight turns on entropy (Shannon’s measure of uncertainty or information content in a probability distribution). When you prompt “The cat sat on the,” the next-token distribution has high probability mass on “mat,” “hat,” “table,” and near-zero probability on “whale” or “ship.” Low entropy, high confidence. But when you write “I’m going out for dinner,” the distribution diffuses across many continuations. High entropy, low confidence. Add “with Martin Casado” and something changes. The phrase is information-rich, the model has seen enough variance of dinner-with-specific-person patterns to compute a Bayesian posterior, and the entropy collapses. If Martin Casado only takes people to Michelin-starred restaurants, the model constrains its predictions accordingly.
This is more than pattern matching. It’s genuine Bayesian reasoning using the prompt as evidence to update distributions over possible completions. The cricket example proves it. Vishal Misra’s custom DSL had never appeared in GPT-3’s training data. He invented it. Yet after seeing six examples, the model generated correct DSL for new queries.
This is in-context learning: the ability to adapt to new tasks from examples provided directly in the prompt, without any model retraining. It had learned structural patterns from other domain-specific languages during training and used his examples as Bayesian evidence to compute posteriors over his particular syntax.
The process is identical whether you’re doing few-shot learning or simple text continuation. There’s no special learning mode. The architecture treats all prompts the same way: as evidence for updating probability distributions.
Why Chain-of-Thought Actually Works
The entropy lens explains why chain-of-thought reasoning (prompting LLMs to show their step-by-step reasoning) succeeds where direct answering fails. Ask someone to compute 769*1,025 and they have a vague guess, a high-entropy distribution over possible answers, almost certainly wrong. But ask them to write it down step-by-step using the multiplication algorithm they learned in school, and suddenly each stage has very low entropy. They know exactly what to do next because they’ve executed this procedure hundreds of times. The algorithm breaks an intractable high-entropy problem into a sequence of trivial low-entropy steps.
LLMs work identically here. Chain-of-thought prompting makes the model break complex problems into small, familiar substeps it has seen during training. Each step becomes a low-entropy decision. The model navigates its learned geometric space with high confidence, arriving at answers it couldn’t reach through direct generation. It’s unrolling embedded procedures that already exist in the training distribution.
The model isn’t creating new reasoning methods. It’s applying known algorithms to new instances. It’s computing what’s already implicit in its training data, not generating fundamentally novel approaches. Vishal Misra calls this the inductive closure of the training set. LLMs can fill in missing rows of the conceptual matrix where algorithms already exist. They can interpolate between training examples with sophistication. They can connect distant results in surprising sequences. What they cannot do is step outside this learned topology.
The Impossibility of Self-Improvement
The AGI question turns decisive with three historical examples:
Any LLM trained on pre-1915 physics could never invent relativity. Einstein didn’t extend Newtonian mechanics, he rejected it. He created the spacetime continuum, a completely new framework for thinking about motion and gravity.
Similarly, quantum mechanics required abandoning classical determinism for wave-particle duality and quantised energy.
Gödel’s incompleteness theorems, which proved that any consistent formal system cannot prove all truths about arithmetic from within itself, demanded stepping outside axiomatic systems to prove their inherent limitation.
Each required inventing new conceptual structures.
Current models can’t do this. Not because they lack parameters or compute or data, but because their architecture only supports navigation within learned spaces.
They traverse solution spaces, connect known results, unroll embedded algorithms. When people talk about recursive self-improvement, they imagine models training on their own outputs and achieving takeoff.
But Vishal Misra’s models show why this fails. A single LLM feeding outputs back as inputs adds no new information. It’s just exploring the same territory. Multiple LLMs talking to each other without external data sources? Still no new information. You’re just combining existing structures, not creating them.
The International Math Olympiad (IMO, the world’s most prestigious mathematics competition for high school students) results look impressive but prove the point. Models solve these problems by exploring solution spaces along low-entropy paths, connecting known mathematical results in novel sequences. They’re not inventing new branches of mathematics or discovering new axioms. They’re navigating with increasing sophistication through known territory. This is hugely valuable, actually transformative for productivity, but it’s not AGI.
Vishal Misra defines AGI simply: “Current models navigate, they do not create. AGI will generate new science, new results, new mathematics.” AGI will happen when an AI system invents something equivalent to relativity or quantum mechanics or proves something like incompleteness, rejecting existing paradigms to establish fundamentally new frameworks. That would be AGI. Until then, we have extremely capable navigation systems getting better at connecting dots within their training distributions.
The Plateau and What Comes Next
Progress has already plateaued, Vishal Misra argues, and not just for one lab. OpenAI, Anthropic, Google, open-source models from Mistral and others all show the same pattern. They’ve become smoother, more reliable, better at staying within their learned topologies. But there’s been no fundamental capability breakthrough. The gains resemble CPU clock speed improvements after Moore’s Law slowed: meaningful for benchmarks, insufficient for paradigm shifts.
Even in coding, where models have the most training data and the highest structural constraints, they hallucinate continuously and require constant supervision. Vishal Misra’s benchmark for belief is simple: “The day an LLM can create a large software project without babysitting, I’ll be convinced it’s approaching AGI. But true AGI requires creation of new science.”
What architectural leap might work? Vishal Misra thinks multimodal inputs help but aren’t sufficient. The problem is scale. Training sets for current LLMs are so enormous that incremental real-world experience can’t meaningfully evolve their learned structures. You’d need massive amounts of fundamentally different data. Simply giving models eyes and ears and embodiment doesn’t solve this.
More promising directions emerge from understanding current failures. Energy-based architectures like Yann LeCun’s Joint Embedding Predictive Architecture framework, which learns by predicting representations in abstract embedding spaces rather than raw pixels or tokens, suggest one path. These systems don’t compress the world into next-token predictions but into energy landscapes where learning means finding stable configurations.
Vishal Misra also points to the ARC Prize (François Chollet’s $1M+ competition based on the Abstraction and Reasoning Corpus, which tests an AI’s ability to acquire new skills efficiently) as diagnostic. Current models fail these tasks badly. “If you understand why the LLMs are failing on this test,” Vishal Misra argues, “maybe you can sort of reverse engineer a new architecture that will help you succeed.” The failures aren’t about missing training data. They’re about lacking the mechanisms for genuine abstraction and rapid generalisation from minimal examples.
The human comparison clarifies what would be the requirements. “When I’m looking at catching a ball that is coming to me, I’m mentally doing that simulation in my head. I’m not translating it to language to figure out where it’ll land. I do that simulation in my head.” This points toward architectures that perform approximate simulations, that test ideas through mental modeling rather than linguistic reasoning. Whether humans developed language because we were intelligent or became intelligent through language remains debated, but language clearly accelerated intelligence by enabling communication and knowledge replication. It’s a networking problem at its core. Yet it’s (probably) not the substrate of thought itself.
Vishal Misra’s most specific architectural intuition: “Language is great but language is not the answer.” The path forward requires systems that can learn with very few examples, the way human brains do, rather than requiring exposure to trillions of tokens. Something must sit on top of LLMs rather than replacing them entirely. The current models remain powerful for navigation within learned spaces. But creating new conceptual frameworks demands different computational principles: approximate simulation, rapid few-shot abstraction, reasoning that doesn’t bottleneck through sequential token prediction.
He’s explicit about uncertainty: “I don’t think I’m not quite in that camp” of believing LLMs are a complete dead end, as Yann LeCun has suggested. Rather, “we need a new architecture to sit on top of LLMs to reach AGI.“ The breakthrough won’t come from throwing more compute at transformers but from hybrid systems that preserve their strengths while adding genuine creative capacity.
Conceptual Toolbox
The Cultural Problem
Vishal Misra submitted his manifold model to a major machine learning conference. The reviewer response: “Okay, this is the model. So what?” They wanted large-scale experiments. He’d provided formal mathematical machinery for understanding how LLMs work, and the field asked for bigger benchmarks.
This captures something about AI research culture. It’s become so easy to build systems and measure them that empiricism dominates. Hundreds of papers change prompts and record outputs. Vishal Misra calls prompt engineering “prompt twiddling” because engineering used to mean achieving five nines reliability or sending humans to the moon. Now it means adjusting adjectives until the model behaves differently.
Without formal understanding, you can’t distinguish fundamental limits from engineering challenges. You can’t tell whether scaling hits a wall or just needs more compute. You can’t separate architecture problems from data problems. The industry is betting hundreds of billions on intuitions that might be wrong. Meanwhile, the people trying to build formal models face review processes that don’t value theoretical contributions unless accompanied by massive empirical validation.
Vishal Misra built Token Probe, a visualisation tool that shows entropy collapsing in real-time as LLMs generate text. You can watch confidence rising with each in-context learning example, see prediction distributions narrowing as prompts become more specific. But the primary contribution isn’t the tool, it’s the framework that explains why the tool shows what it shows.
Orthogonal Implications
The manifold model reveals something about learning itself. In-context learning isn’t a special mode, it’s the same Bayesian update mechanism LLMs use for all text generation. This means you can’t “turn on” learning by prompt engineering alone. The model either has structural patterns in its training data that your examples activate, or it doesn’t. Few-shot examples work when they provide evidence that shifts the posterior distribution into higher-confidence regions. They fail when no relevant training patterns exist.
This has direct implications for RAG systems and fine-tuning strategies. RAG works not because you’re adding knowledge to the model but because you’re providing evidence that collapses entropy in useful ways. The retrieved documents shift probability distributions over completions. Fine-tuning works when it fills in missing regions of the learned topology with targeted training data. Neither approach can create entirely new conceptual structures. They improve navigation within existing ones.
There’s also a definitional angle that cuts through AGI debates. With billions in capital, you can collect enough data to make models excellent at any specific domain. Want materials science breakthroughs? Fund massive materials data collection and fine-tune aggressively. Want better drug discovery? Same approach. This looks like creation, but it’s just expansion through targeted data. The test shouldn’t be capability on specific benchmarks but whether the system ever produces outputs that fall outside what’s computable from training distributions. So far, that hasn’t happened. Every impressive demo traces back to sophisticated interpolation and connection of training data.
Beyond Silicon Valley Assumptions
Vishal Misra’s work sits at an intersection that Silicon Valley often misses. His background is networking theory, information theory, formal systems. He thinks in terms of Shannon entropy and Bayesian posteriors. This gives him analytical tools the ML community doesn’t typically use and makes him skeptical of claims that can’t be formalised.
It also makes him representative of a research tradition that values theoretical clarity over empirical scale. The best network protocols came from people who could prove properties formally, not just measure performance. The best compression algorithms came from information theory, not trial and error. Vishal Misra thinks AI needs similar rigor. Not instead of empirical work, but alongside it. The field needs both people who build bigger models and people who explain why those models work.
A close intellectual analog in AI might be Judea Pearl‘s work on causal reasoning or Yann LeCun’s recent focus on energy-based models. These researchers also try to formalise what learning systems can and cannot do, moving beyond empirical pattern recognition toward mechanistic understanding. Vishal Misra’s contribution is bringing information theory and geometric reasoning to LLM analysis specifically.
Vishal Misra’s critique of the field’s empiricism tracks with his critique of recursive self-improvement claims. Both mistake measurement for understanding. Just as you can’t engineer reliable systems through prompt twiddling, you can’t achieve AGI through scaling alone if the architecture has fundamental limits. The question isn’t whether models will get better with more compute (they will) but whether they’ll cross the threshold into creating genuinely new frameworks (they probably won’t without architectural change).
His work resonates with growing skepticism about scaling as the path to AGI, but from a more rigorous foundation than most critiques. Gary Marcus argues LLMs lack systematic generalisation, but often from behavioral observations rather than formal models. François Chollet argues intelligence requires abstraction and reasoning, demonstrated through ARC, but again primarily through empirical tests. Vishal Misra provides mathematical machinery that explains why certain behaviours emerge and why others can’t, regardless of scale.
There’s also an interesting limitation to his framework. It explains what LLMs can’t do more clearly than what future architectures might accomplish. The problem of creating new conceptual structures is well-specified. What solves it remains speculative. Energy-based models, simulation-based reasoning, few-shot learning mechanisms, all these point in promising directions without guaranteeing success. This leaves practical questions open.
Closing Notes
Formal models shows that current architectures hit a mathematical wall.
No amount of scaling changes the fundamental constraint that LLMs navigate learned topologies rather than create new ones.
The hundred-billion-dollar bets on pure scaling assume a path that Misra’s framework suggests doesn’t exist. But the clarity on limits also suggests direction. Hybrid systems that layer creative mechanisms atop powerful navigation engines, architectures that perform approximate simulation rather than pure linguistic reasoning, frameworks that learn from minimal examples rather than trillion-token corpora - these point toward genuine breakthroughs rather than incremental improvements. As Misra puts it: “AGI will create new manifolds. Current models navigate, they do not create. When an AI comes up with a theory of relativity, it has to go beyond what it has been trained on to come up with new paradigms, new science. That’s by definition AGI.” The question for the field isn’t whether to abandon transformers but what to build on top of them. The question for investors isn’t whether AI will transform industries, it already is, but which architectural bets lead beyond navigation toward genuine creation. Misra’s models don’t answer that question, but they clarify what it actually requires.
Article originally posted on WeLoveSota.com